Ruby Read File Lines and Write Distinct Values
Introduction
This post volition cover chief tools and techniques for web scraping in Scarlet. We start with an introduction to building a web scraper using common Crimson HTTP clients and parsing the response. This approach to web scraping has, nevertheless, its limitations and tin can come with a fair dose of frustration. Not to mention, equally manageable as it is to scrape static pages, these tools fail when information technology comes to dealing with Single Page Applications, the content of which is built with JavaScript. As an answer to that, we will propose using a consummate web scraping framework. This commodity assumes that the reader is familiar with fundamentals of Ruby and of how the Net works.
Note: Although there is a multitude of gems, nosotros will focus on those most pop equally indicated by their Github "used past", "star" and "fork" attributed. While we won't exist able to cover all the usecases for these tools, nosotros volition provide skilful grounds for yous to go started and explore more on your own.
Part I: Static pages
Setup
In social club to exist able to lawmaking along with this part, you may demand to install the following gems:
precious stone install 'pry' #debugging tool gem install 'nokogiri' #parsing gem gem install 'HTTParty' #HTTP asking gem Moreover, we volition use open-uri, net/http and csv, which are part of the standard Ruby library so there's no demand for a separate installation.
I will place all my code in a file chosen scraper.rb.
Note: My carmine version is 2.half dozen.1
Brand a request with HTTP clients in Carmine
In this department, nosotros will cover how to scrape Wikipedia with Ruby.
Imagine you want to build the ultimate Douglas Adams fan wiki. You would for sure showtime with getting data from Wikipedia. In order to send a request to any website or spider web app, yous would need to employ an HTTP customer. Let'south take a expect at our three main options: cyberspace/http, open up-uri and HTTParty. You can use whichever of the beneath clients you like the most and it will work with the step 2.
Internet/HTTP
Carmine standard library comes with an HTTP client of its own, namely, the net/http jewel. In order to brand a request to Douglas Adams Wikipedia folio easily, nosotros demand to first prepare the URL. To do so, nosotros will employ the open-uri gem, which also is a office of the standard Ruby library.
# you shouldn't demand to require these gems but but in case: # crave 'open up-uri' # require 'net/http' url = "https://en.wikipedia.org/wiki/Douglas_Adams" uri = URI .parse(url) response = Net :: HTTP .get_response(uri) puts response.body #=> "\n<!DOCTYPE html>\north<html class=\"customer-nojs\" lang=\"en\" dir=\"ltr\">\n<head>\n<meta charset=\"UTF-viii\"/>\n<title>Douglas Adams - Wikipedia</title>..." We are given a string with all the html from the page.
Note: If the information comes in a json format, you can parse it by adding these two lines:
require 'json' JSON .parse(response.body) That's it - information technology works! All the same, the syntax of net/http is a bit clunky and less intuitive than that of HTTParty or open-uri, which are, in fact, just elegant wrappers for cyberspace/http.
HTTParty
The HTTParty gem was created to 'make http fun'. Indeed, with the intuitive and straightforward syntax, the gem has become widely popular in recent years. The following two lines are all we need to make a successful GET request:
require "HTTParty" html = HTTParty .get("https://en.wikipedia.org/wiki/Douglas_Adams") # => "<!DOCTYPE html>\n" + "<html form=\"client-nojs\" lang=\"en\" dir=\"ltr\">\north" + "<head>\n" + "<meta charset=\"UTF-viii\"/>\northward" + "<championship>Douglas Adams - Wikipedia</title>\n" + ... What is returned is a HTTParty::Response, an array-like drove of strings representing the html of the page.
Note: Information technology is much easier to work with objects. If the response Content Type is application/json, HTTParty volition parse the response and render Ruby objects with keys as strings. Nosotros tin can learn almost the content type by running response.headers["content-type"]. In gild to achieve that, we demand to add this line to our code:
JSON .parse response, symbolize_names: true We tin can't, however, practice this with Wikipedia as nosotros get text/html back.
We wrote an all-encompassing guide about the best Ruddy HTTP clients, experience free to cheque it out.
Open URI
The simplest solution, all the same, is making a asking with the open up-uri jewel, which too is a office of the standard Scarlet library:
crave 'open-uri' html = open("https://en.wikipedia.org/wiki/Douglas_Adams") ##<File:/var/folders/zl/8zprgb3d6yn_466ghws8sbmh0000gq/T/open up-uri20200525-33247-1ctgjgo> The render value is a Tempfile containing the HTML and that's all nosotros demand for the next step. It is just i line.
The simplicity of open-uri is already explained in its name. It only sends one type of request, and does information technology very well: with a default SSL and following redirections.
Parsing HTML with Nokogiri
In one case we have the HTML, nosotros demand to excerpt but the parts that are of our interest. As you probably noticed, each of the routes in the previous section has declared the html variable. Nosotros will use information technology now every bit an argument to Nokogiri::HTML method.
response = Nokogiri :: HTML(html) # => #(Document:0x3fe41d89a238 { # name = "document", # children = [ # #(DTD:0x3fe41d92bdc8 { name = "html" }), # #(Element:0x3fe41d89a10c { # proper noun = "html", # attributes = [ # #(Attr:0x3fe41d92fe00 { name = "class", value = "client-nojs" }), # #(Attr:0x3fe41d92fdec { proper noun = "lang", value = "en" }), # #(Attr:0x3fe41d92fdd8 { name = "dir", value = "ltr" })], # children = [ # #(Text "\n"), # #(Element:0x3fe41d93e7fc { # proper noun = "head", # children = [ ... Here the return value is Nokogiri::HTML::Document, a hash-like object, which is actually a snapshot of that HTML converted into a structure of nested nodes.
The practiced news is that Nokogiri allows us to utilise CSS selectors or XPath to target the desired element. We will use both the CSS selectors and the XPath.
In order to parse through the object, we need to practise a fleck of a detective work with the browser's DevTools. In the below instance, nosotros am using Chrome to inspect whether a desired element has any attached grade:
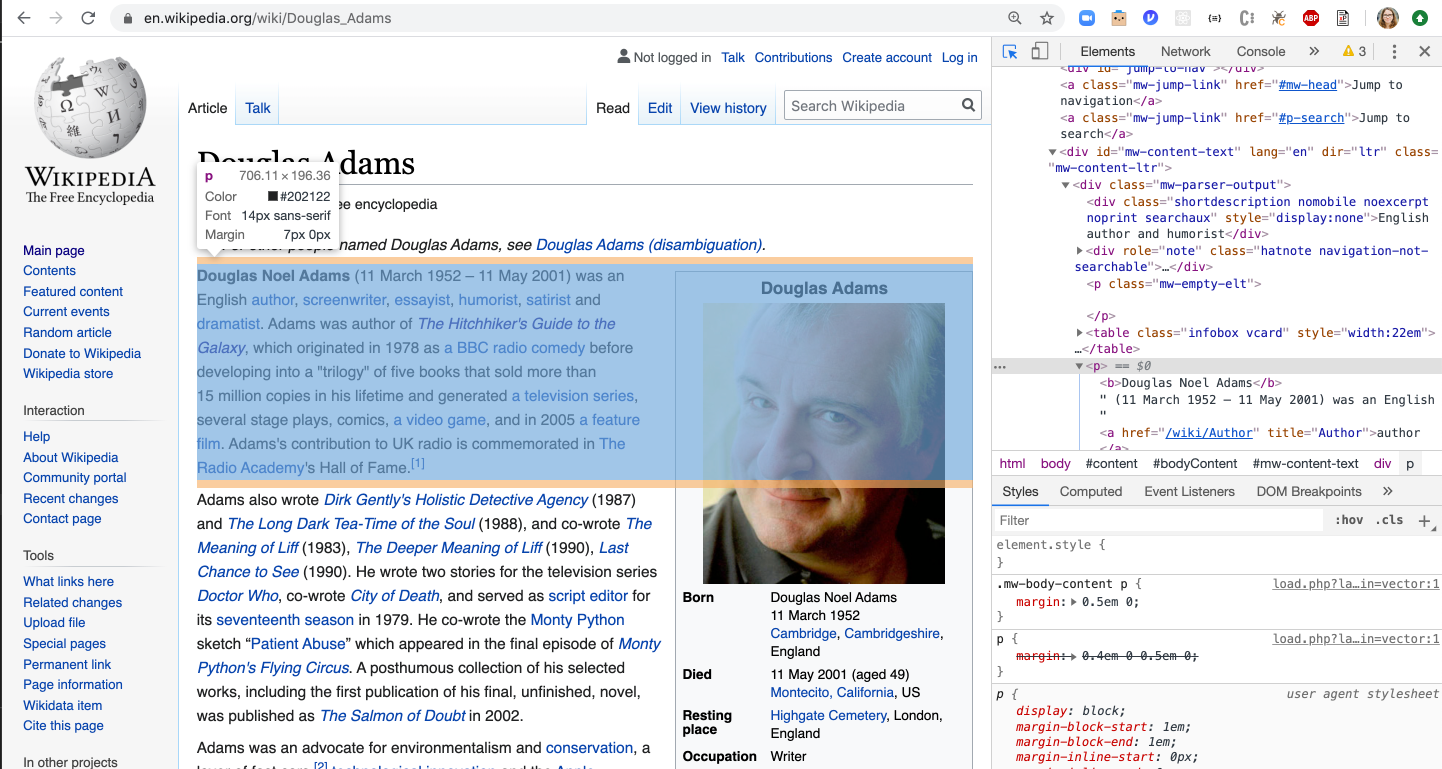
Equally we come across, the elements on Wikipedia do not have classes. Still, we tin target them past their tag. For case, if we wanted to get all the paragraphs, we'd approach information technology by starting time selecting all p keys, and so converting them to text:
description = doc.css("p").text # => "\n\nDouglas Noel Adams (eleven March 1952 – 11 May 2001) was an English author, screenwriter, essayist, humorist, satirist and dramatist. Adams was author of The Hitchhiker's Guide to the Galaxy, which originated in 1978 equally a BBC radio comedy earlier developing into a \"trilogy\" of v books that sold more than 15 million copies in his lifetime and generated a television series, several stage plays, comics, a video game, and in 2005 a feature film. Adams'due south contribution to UK radio is commemorated in The Radio University's Hall of Fame.[1]\nAdams also wrote Dirk Gently'south... This arroyo resulted in a 4,336-give-and-take-long string. Nevertheless, imagine you would like to go merely the start introductory paragraph and the pic. You could either use regex or let Reddish do this for you with the .carve up method. Here we see that the demarcation for paragraphs (\n) have been preserved. We tin therefore ask Cerise to extract simply the beginning non-empty paragraph:
description = md.css("p").text.divide(" \n ").find{|due east| e.length > 0} Alternatively, nosotros can likewise simply become rid of any empty spaces past calculation the .strip method and then just selecting the first item:
description = doctor.css("p").text.strip.split(" \n ")[ 0 ] Alternatively, and depending on how the HTML is structured, sometimes an easier way could be traversing it by accessing the XML (Extensible Markup Language), which is the format of the Nokogiri::HTML::Document. To do that, nosotros'd select one of the nodes and dive as deep as necessary:
description = physician.css("p")[ 1 ] #=> #(Chemical element:0x3fe41d89fb84 { # proper noun = "p", # children = [ # #(Element:0x3fe41e43d6e4 { proper name = "b", children = [ #(Text "Douglas Noel Adams")] }), # #(Text " (11 March 1952 – 11 May 2001) was an English "), # #(Element:0x3fe41e837560 { # name = "a", # attributes = [ # #(Attr:0x3fe41e833104 { name = "href", value = "/wiki/Author" }), # #(Attr:0x3fe41e8330dc { name = "championship", value = "Writer" })], # children = [ #(Text "author")] # }), # #(Text ", "), # #(Element:0x3fe41e406928 { # name = "a", # attributes = [ # #(Attr:0x3fe41e41949c { name = "href", value = "/wiki/Screenwriter" }), # #(Attr:0x3fe41e4191cc { name = "title", value = "Screenwriter" })], # children = [ #(Text "screenwriter")] # }), Once we establish the node of our interest, nosotros want to call the .children method on it, which volition render -- yous've guessed it -- more nested XML objects. Nosotros could iterate over them to get the text we need. Here's an case of return values from 2 nodes:
doc.css("p")[ 1 ].children[ 0 ] #=> #(Element:0x3fe41e43d6e4 { name = "b", children = [ #(Text "Douglas Noel Adams")] }) dr..css("p")[ 1 ].children[ 1 ] #=> #(Text " (xi March 1952 – eleven May 2001) was an English ") At present we want to call .children method, which will return -- you've guessed information technology -- nested XML objects and we could iterate over them to become the text we demand. Here'southward an example of return values from two nodes:
md.css("p")[ 1 ].children[ 0 ] #=> #(Element:0x3fe41e43d6e4 { proper noun = "b", children = [ #(Text "Douglas Noel Adams")] }) doc.css("p")[ 1 ].children[ 1 ] #=> #(Text " (11 March 1952 – eleven May 2001) was an English language ") Now, let'south locate the moving-picture show. That should exist easy, right? Well, since there are no classes or ids on Wikipedia, calling doc.css('img') resulted in 16 elements, and increasing selector specificity to doctor.css('td a img') still did non allow us to get the main image. We could await for the epitome past its alt text and then save its url:
motion picture = doc.css("td a img").find{|picture| picture.attributes[ "alt" ].value.include?("Douglas adams portrait cropped.jpg")}.attributes[ "src" ].value Or we could locate the image using the XPath, which also returns eigtht objects so we need to find the correct 1:
pic = doc.xpath("/html/body/div[3]/div[3]/div[iv]/div/tabular array[one]/tbody/tr[2]/td/a/img").discover{|picture| picture.attributes[ "alt" ].value.include?("Douglas adams portrait cropped.jpg")}.attributes[ "src" ].value While all this is possible to achieve, it is really time consuming and a pocket-size change in the page html tin result in our code breaking. Hunting for a specific piece of text, with or without regex, oftentimes feels like looking for a few needles in haystack. To add to that, frequently the websited themselves are not structured in a logical way and do not follow clear design. That non simply prolongs the time a developer spends with DevTools but also results in many exceptions.
Fortunately, a programmer's feel definitely improves when using a web scraping framework, which not only makes the lawmaking cleaner but likewise has ready-fabricated tools for all occassions.
💡 We released a new feature that makes this whole procedure fashion simpler. You tin now extract data from HTML with one uncomplicated API telephone call. Experience free to cheque the documentation here.
Exporting Scraped Data to CSV
Before we move on to covering the complete web scraping framework, let's just come across how to actually use the information we go from a website.
Once you've successfully scraped the website, you can save it equally a CSV list, which tin can exist used in Excel or integrated into e.m. a mailing platform. It is a popular apply case for web scraping. In social club to implement this feature, you will apply the csv gem.
- In the same folder, create a separate
data.csvfile. -
csvworks best with arrays then create adata_arrayvariable and ascertain information technology as an empty assortment. - Push the information to the assortment.
- Add together the array to the
csvfile. - Run the scraper and check your
data.csvfile.
The code:
crave 'csv' html = open("https://en.wikipedia.org/wiki/Douglas_Adams") doc = Nokogiri :: HTML(html) data_arr = [] description = doc.css("p").text.dissever(" \due north ").discover{|eastward| e.length > 0} movie = doc.css("td a img").find{|pic| picture.attributes[ "alt" ].value.include?("Douglas adams portrait cropped.jpg")}.attributes[ "src" ].value data_arr.push([clarification, picture]) CSV .open('data.csv', "w") do |csv| csv << data terminate Part Ii: A complete Reddish spider web scraping framework
We have covered scraping static pages with basic tools, which forced u.s.a. to spend a chip too much time on trying to locate a specific element. While these approaches more-or-less work, the do have their limitations. For instance, what happens when a website depens on JavaScript, like in the case of Unmarried Page Applications, or the space curlicue pages? These web apps usually have very limited initial HTML and and then scraping them with Nokogiri would not bring the desired effects.
In this instance, we could employ a framework that works with JS-rendered sites. The friendliest and all-time-documented one is past far Kimurai, which runs on Nokogiri for static pages and Capybara for imitating user interaction with the website. Apart from a plethora of helper methods for making web scraping easy and pleasant, it works out of the box with Headless Chrome, Firefox and PhantomJS.
In this function of the commodity, we volition scrape a job listing spider web app. Kickoff, nosotros will do it statically by just visiting dissimilar URL addresses and then, nosotros will introduce some JS action.
Kimurai Setup
In order to scrape dynamic pages, you demand to install a couple of tools -- beneath you lot will find the list with the MacOS installation commands:
- Chrome and Firefox:
brew cask install google-chrome firefox - chromedriver:
brew cask install chromedriver - geckodriver:
brew install geckodriver - PhantomJS:
brew install phantomjs - Kimurai gem:
gem install kimurai
In this tutorial, nosotros will employ a unproblematic Ruby file but you could also create a Rails app that would scrape a site and save the data to the database.
Static page scraping
Let's starting time with what Kimurai considers a bare minimum: a course with options for the scraper and a parse method:
require 'kimurai' course JobScraper < Kimurai :: Base @name= 'eng_job_scraper' @start_urls = [ "https://www.indeed.com/jobs?q=software+engineer&fifty=New+York%2C+NY" ] @engine = :selenium_chrome def parse(response, url:, information: {}) end end As yous see above, we use the following options:
-
@proper name: you can name your scraper whatever you wish or omit information technology altogether if your scraper consists of just one file; -
@start_urls: this is an array of start urls, which will be processed one past i inside theparsemethod; -
@engine: engine used for scraping; in this tutorial, we are using Selenium with Headless Chrome; if you lot don't know, which engine to choose, cheque this description of each one.
Let's talk almost the parse method at present. It is a is the default start method for the scraper and it accepts the following arguments:
-
response: theNokogiri::HTMLobject, which we know from the prior part of this mail; -
url: a string, which tin can be either passed to the method manually or otherwise volition be taken from the@start_urlsarray; -
data: a storage for passing data betwixt requests;
Just like when nosotros used Nokogiri, here y'all can also parse the response by using CSS selectors or XPath. If you're non very familiar with the XPath, here is a practical guide to XPath for web scraping. In this role of the tutorial we will use both.
Before we move on, we need to introduce the browser object. Every instance method of the scraper has an access to the Capybara::Session object. Although usually it is not necessary to use it (considering response already contains the whole page), if you want ultimately be able to click or fill out forms, it allows you to interact with the website.
Now would be a good fourth dimension to have a expect at the Page structure:
Since nosotros are only interested in the job listings, information technology is convenient to come across whether they are groupped within a component -- in fact, they are all nested in td#resultsCol. After locating that, we practise the aforementioned with each of the listings. Below you volition also encounter a helper method scrape_page and a @@jobs = [] array, which will be our storage for all the jobs we scrape.
require 'kimurai' course JobScraper < Kimurai :: Base @proper name= 'eng_job_scraper' @start_urls = [ "https://world wide web.indeed.com/jobs?q=software+engineer&50=New+York%2C+NY" ] @engine = :selenium_chrome @@jobs = [] def scrape_page dr. = browser.current_response returned_jobs = dr..css('td#resultsCol') returned_jobs.css('div.jobsearch-SerpJobCard').each practice |char_element| #code to go just the listings stop finish def parse(response, url:, information: {}) scrape_page @@jobs end end JobScraper .crawl! Allow'south inspect the page once more to check the selectors for championship, clarification, company, location, bacon, requirements and the slug for the listing:
With this noesis, we can scrape an individual listing.
def scrape_page doc = browser.current_response returned_jobs = doctor.css('td#resultsCol') returned_jobs.css('div.jobsearch-SerpJobCard').each do |char_element| # scraping individual listings championship = char_element.css('h2 a')[ 0 ].attributes[ "title" ].value.gsub(/\north/, "") link = "https://indeed.com" + char_element.css('h2 a')[ 0 ].attributes[ "href" ].value.gsub(/\n/, "") clarification = char_element.css('div.summary').text.gsub(/\n/, "") company = description = char_element.css('span.company').text.gsub(/\n/, "") location = char_element.css('div.location').text.gsub(/\n/, "") salary = char_element.css('div.salarySnippet').text.gsub(/\n/, "") requirements = char_element.css('div.jobCardReqContainer').text.gsub(/\northward/, "") # creating a task object job = {title: championship, link: link, description: description, visitor: visitor, location: location, bacon: bacon, requirements: requirements} # calculation the object if it is unique @@jobs << task if !@@jobs.include?(job) terminate end Instead of creating an object, we could also create an array, depending on what data structure we'd need subsequently:
job = [title, link, description, visitor, location, salary, requirements] As the code currently is, nosotros but get the offset xv results, or but the first page. In order to get information from the next pages, we can visit subsequent URLs:
def parse(response, url:, information: {}) # scrape first page scrape_page # next folio link starts with twenty so the counter will be initially gear up to 2 num = two #visit next folio and scrape it 10 .times practise browser.visit("https://www.indeed.com/jobs?q=software+engineer&l=New+York,+NY&start= #{num} 0") scrape_page num += ane end @@jobs end Last but not to the lowest degree, we could create a JSON or CSV files by adding these snippets to the parse method to store the scraped data:
CSV .open up('jobs.csv', "w") exercise |csv| csv << @@jobs finish or:
File .open("jobs.json","due west") practice |f| f.write(JSON .pretty_generate(@@jobs)) end Dynamic page scraping with Selenium and Headless Chrome
In bringing JavaScript interaction, we actually won't change much almost our current lawmaking except that instead of visiting different URLs, we will apply Selenium with headless Chrome to imitate a user interaction and click the button that will have usa in that location.
def parse(response, url:, data: {}) 10 .times practice # scrape get-go page scrape_page puts "🔹 🔹 🔹 CURRENT NUMBER OF JOBS: #{@@jobs.count} 🔹 🔹 🔹" # find the "side by side" button + click to move to the next page browser.discover('/html/body/tabular array[two]/tbody/tr/td/table/tbody/tr/td[one]/nav/div/ul/li[six]/a/span').click puts "🔺 🔺 🔺 🔺 🔺 CLICKED THE NEXT Button 🔺 🔺 🔺 🔺 " end @@jobs end To this end we utilize two methods:
-
find(): finding an element in the current session past itsXPath; -
click: simulating user interaction.
Nosotros added 2 puts statements to see whether our scraper actually moves forward:

Equally yous see, we successfully scraped the first page but then we encountered an error:
element click intercepted: Element <span grade= "pn">...</span> is non clickable at point (329, 300). Other element would receive the click: <input autofocus= "" name= "email" blazon= "email" id= "popover-e-mail" course= "popover-input-locationtst"> (Selenium::WebDriver::Error::ElementClickInterceptedError) (Session info: headless chrome=83.0.4103.61) We could either investigate the response to read the HTML and attempt to understand why the page looks differently or nosotros could use a more elaborate tool, a screenshot of the page:
def parse(response, url:, information: {}) x .times exercise # scrape start page scrape_page # take a screenshot of the page browser.save_screenshot # observe the "next" push + click to move to the next folio browser.observe('/html/body/table[2]/tbody/tr/td/table/tbody/tr/td[1]/nav/div/ul/li[6]/a/bridge').click puts "🔹 🔹 🔹 Electric current NUMBER OF JOBS: #{@@jobs.count} 🔹 🔹 🔹" puts "🔺 🔺 🔺 🔺 🔺 CLICKED THE NEXT BUTTON 🔺 🔺 🔺 🔺 " end @@jobs finish Now, as the code runs, nosotros get screenshots of every page it encounters. This is the first page:

And here is the second page:
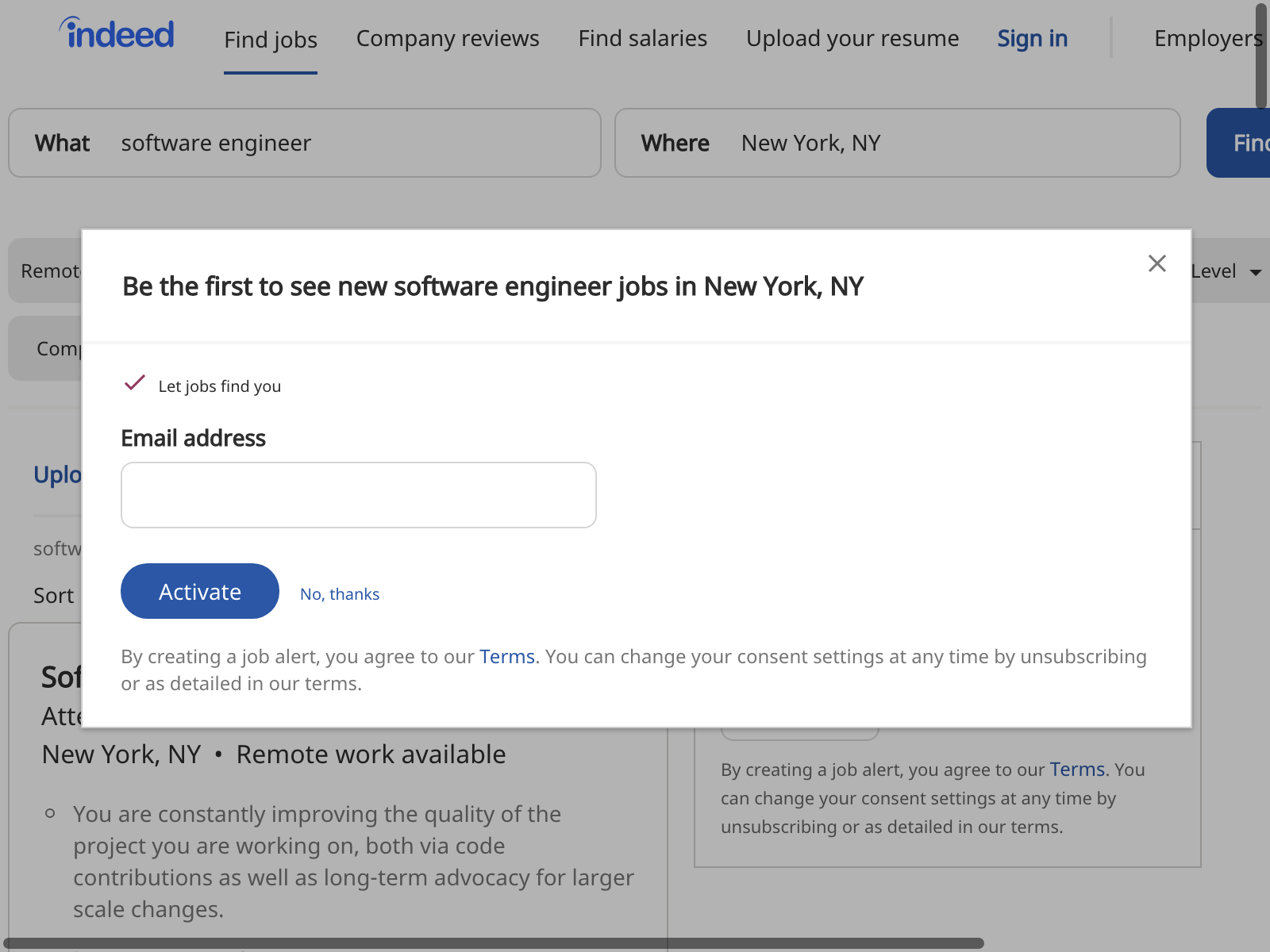
Aha! A popup! After running this exam a couple of times, and inspecting errors closely, we know that information technology comes in 2 versions and that, sadly, it is not clickable. However, we can always refresh the page and the information of our annoyance will be saved in the session. Let's then add a safeguard:
def parse(response, url:, data: {}) 10 .times do scrape_page # if there's the popup, escape it if browser.current_response.css('div#popover-background') || browser.current_response.css('div#popover-input-locationtst') browser.refresh end # find the "side by side" button + click to move to the next page browser.find('/html/body/table[ii]/tbody/tr/td/tabular array/tbody/tr/td[i]/nav/div/ul/li[6]/a/bridge').click puts "🔹 🔹 🔹 CURRENT NUMBER OF JOBS: #{@@jobs.count} 🔹 🔹 🔹" puts "🔺 🔺 🔺 🔺 🔺 CLICKED THE Side by side BUTTON 🔺 🔺 🔺 🔺 " terminate @@jobs finish Finally, our scraper works without a problem and later on x rounds, we end up with 155 chore listings:
Here'due south the full code of our dynamic scraper:
crave 'kimurai' class JobScraper < Kimurai :: Base @name= 'eng_job_scraper' @start_urls = [ "https://www.indeed.com/jobs?q=software+engineer&50=New+York%2C+NY" ] @engine = :selenium_chrome @@jobs = [] def scrape_page doc = browser.current_response returned_jobs = dr..css('td#resultsCol') returned_jobs.css('div.jobsearch-SerpJobCard').each practice |char_element| championship = char_element.css('h2 a')[ 0 ].attributes[ "championship" ].value.gsub(/\n/, "") link = "https://indeed.com" + char_element.css('h2 a')[ 0 ].attributes[ "href" ].value.gsub(/\due north/, "") description = char_element.css('div.summary').text.gsub(/\n/, "") company = description = char_element.css('span.company').text.gsub(/\n/, "") location = char_element.css('div.location').text.gsub(/\n/, "") salary = char_element.css('div.salarySnippet').text.gsub(/\due north/, "") requirements = char_element.css('div.jobCardReqContainer').text.gsub(/\northward/, "") # chore = [championship, link, description, company, location, salary, requirements] task = {title: championship, link: link, description: description, company: company, location: location, salary: salary, requirements: requirements} @@jobs << task if !@@jobs.include?(chore) end finish def parse(response, url:, data: {}) 10 .times do scrape_page if browser.current_response.css('div#popover-background') || browser.current_response.css('div#popover-input-locationtst') browser.refresh end browser.find('/html/body/tabular array[2]/tbody/tr/td/tabular array/tbody/tr/td[i]/nav/div/ul/li[six]/a/span').click puts "🔹 🔹 🔹 Electric current NUMBER OF JOBS: #{@@jobs.count} 🔹 🔹 🔹" puts "🔺 🔺 🔺 🔺 🔺 CLICKED Next BUTTON 🔺 🔺 🔺 🔺 " end CSV .open up('jobs.csv', "w") do |csv| csv << @@jobs end File .open up("jobs.json","w") exercise |f| f.write(JSON .pretty_generate(@@jobs)) end @@jobs end end jobs = JobScraper .clamber! Alternatively, you could also replace the clamber! method with parse!, which would allow you to use the return statement and print out the @@jobs array:
jobs = JobScraper .parse!(:parse, url: "https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY") pp jobs Conclusion
Web scraping is definitely i of the most powerful activities a developer can engange equally it helps you speedily access, agregate and procedure data coming from various sources. It tin feel satisfying or daunting, depending on the tools one's using as some can see through poor web pattern decisions and deliver just the data y'all need in the matter of seconds. I definitely do not wish anyone to spend hours trying to scrape a page just to learn that there are sometimes small inconsistencies in how their developers approached web development. Look for tools that make your life easier!
While this whole article tackles the main aspect of web scraping with Ruby, it does non talk about web scraping without getting blocked.
If you want to learn how to do it, we have wrote this complete guide, and if you don't want to take intendance of this, you can always use our web scraping API.
Happy Scraping.
Read more
- Carmine web scraping gems
- Nokogiri
- Kimurai
- Practical XPath for web scraping
- Parsing Nokogiri response with CSS or XPath
-
Capybara::Sessionobject
Source: https://www.scrapingbee.com/blog/web-scraping-ruby/
0 Response to "Ruby Read File Lines and Write Distinct Values"
Post a Comment